Data Pipeline Creation
ActionIQ
Summary
Working with internal engineers and clients’ data engineering team, I designed a new workflow to set up new data pipelines in ActionIQ. This workflow replaces the need to write custom scripts for every new data pipeline, and includes a versioning capability.
Background

ActionIQ clients’ data pipelines consist of data ingestions & transformations. These are currently configured, tested, and deployed by ActionIQ's Field Engineering team. Clients have to submit service requests whenever they want to have a new pipeline for new data sets.
The objective of this project is to enable users to set up new data pipelines on their own.
Role
UX & UI Design – Designed both the UX of setting up new data pipelines as well as the UI for the workflow.
User Research – Conducted discovery user research & usability testing
Research
Discovery & Usability Test
During discovery stage, I worked with Backend and Field Engineers to map ActionIQ’s end-to-end data ingestion & transformation workflows.

After discovery & prototyping, I conducted usability tests with target users (clients’ Data Teams). They were asked to complete a new pipeline creation workflow.

Design Outcomes
Versioning
In ActionIQ’s platform, data tables can be used as building blocks for other data tables. Making changes to a table, hence, could have unforeseen downstream impact. Users (data engineers) need a way to create, test and validate updates without affecting their production environment.
Taking cues from git, we designed a versioning feature as a prerequisite to the data pipeline creation workflow. With versioning, multiple users can work independently, create new data tables, and only merge to the production branch after the testing and review process.
Job-Centric -> Object Centric Workflows
There are two components in ActionIQ data pipelines:
Ingest jobs: getting data tables from a data source into ActionIQ’s platform
Transformation jobs: applying arbitrary SQL transformations and modeling the tables, so that they can be queried by ActionIQ’s query engine and used by other users on the platform.
We found that setting up jobs was not intuitive for users, and so we designed an object-centric workflow instead of a job-centric one. Instead of configuring jobs, users configure Source Tables (outcome of ingest jobs) and Transformed Tables (outcome of transformation jobs).
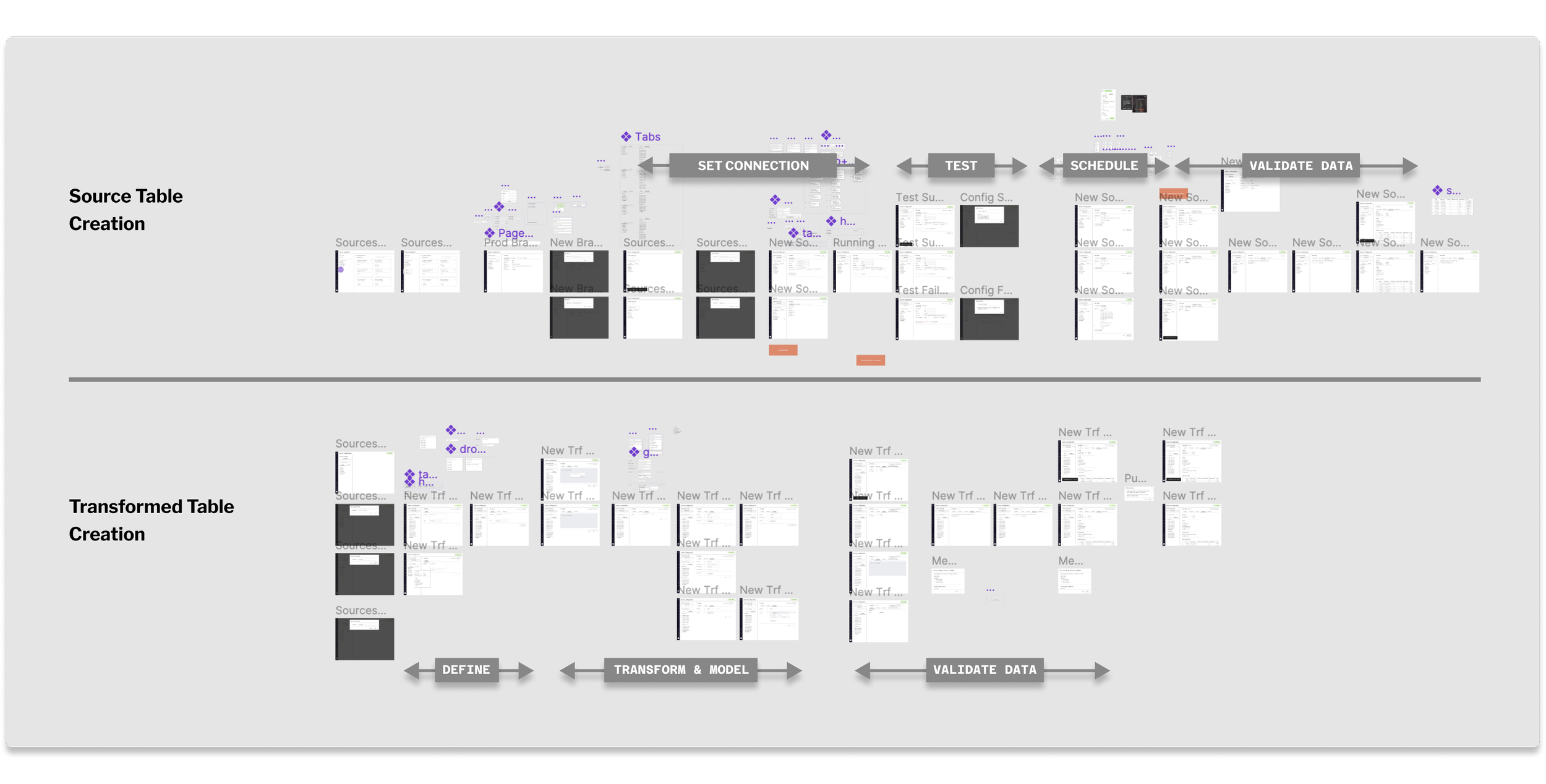
This also allows users the flexibility to treat the different Tables as Lego-like building blocks. For example, users can choose to partition one Source Table into two Transformed Tables, by applying a date or location filter.
Impact
2 weeks → 2 days
Improved avg. time-to-completion
Adoption rate amongst technical users
34%
“This is pretty straight forward! I’m sure with this design I can figure out how to set up a new table in 20 minutes.”
–Data Engineer
“This is easy to understand. The workflow is simpler compared to other products in the market.”
–Data Engineer